A Model Codebase: Flying Tulip's Launch and Sherlock Audit Contest
Flying Tulip brought its ftPUT contracts to Sherlock for a final audit contest before launch. Hundreds of researchers reviewed the code, with zero valid Medium or High severity findings after judging.
.png)
When @AndreCronjeTech builds something, the industry pays attention.
The founder of Yearn Finance and architect behind Sonic has spent years shaping how decentralized finance gets built at scale. So when his latest venture, @flyingtulip_, came to Sherlock for an audit contest on its ftPUT contracts as a final stress-test before launch, the bar was high from the start.
The contest wrapped up with zero valid Medium or High severity findings, making it one of the cleanest contest outcomes we have seen on Sherlock.
That kind of result usually comes from what happens before the contest: serious engineering, multiple rounds of security review, and a team willing to put hardened code in front of a public researcher community.
The ftPUT: A $1B+ Redemption Contract
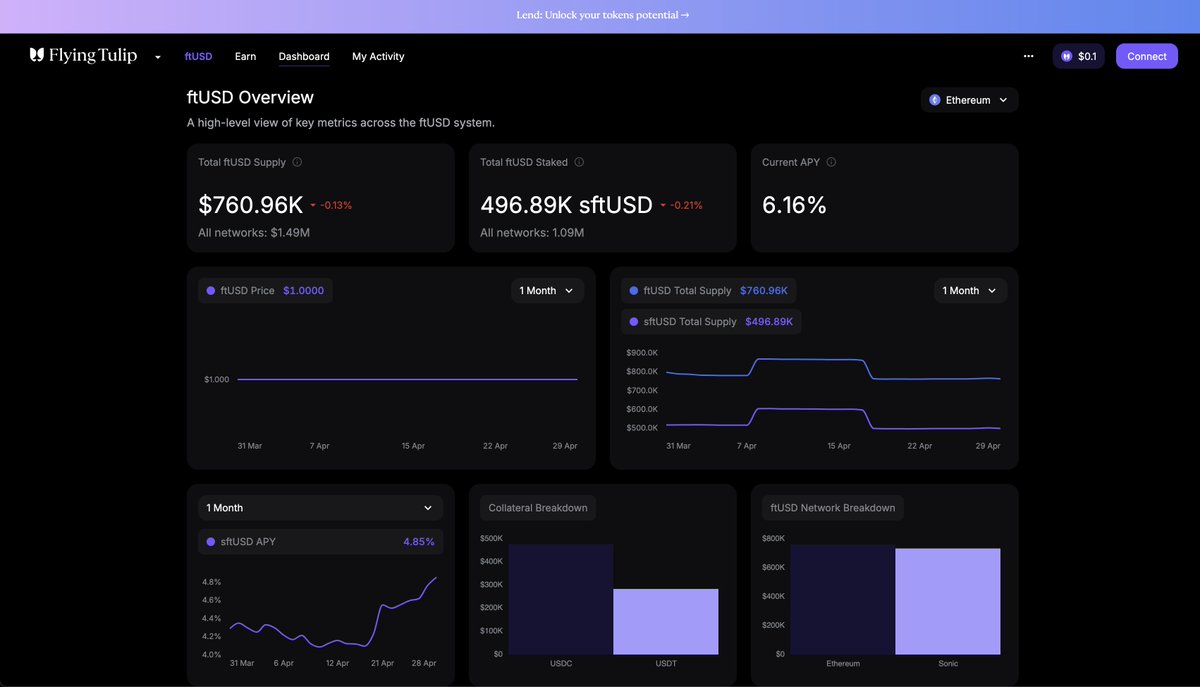
Flying Tulip is an onchain financial system that unifies spot trading, lending, perpetual futures, insurance, and settlement into a single capital-efficient protocol. The project raised $200M at a $1B token valuation from firms including Amber Group, CoinFund, FalconX, Nascent, and Susquehanna, and launched its public token sale in February 2026 after a heavily oversubscribed CoinList pre-sale.
At the heart of that sale is the ftPUT, a mechanism that gives every token holder a perpetual put option at their original purchase price. Buyers can redeem their initial investment at par, at any time, through a permissionless smart contract interaction. No lockup. No fee. Full liquidity. The contract is designed to hold potentially $1B+ in redeemable value, meaning the code securing it needed the highest level of scrutiny.
As of mid-April 2026, the protocol is already live on Ethereum and Sonic, generating over $638K in PUT revenue, with $1.19M in ftUSD minted and over 11M FT bought and burned. Margin lending launched in early April. Real capital, real yield, real usage, all flowing through the contracts that just went through our audit process.
Why Flying Tulip Came to Sherlock
Flying Tulip didn't rely on a single audit and call it a day. They did what very few teams actually follow through on: they ran the full security pipeline before going to mainnet.
It started with several rounds of traditional audits from established security firms. Each engagement gave the developers direct feedback loops to harden the codebase before wide-scale public scrutiny. Then, as a final pressure-test came the Sherlock audit contest, which opened the code to competitive review from hundreds of independent security researchers, with $100,000 USDC in rewards on the line.
After the contest, Flying Tulip launched a bug bounty program to provide ongoing coverage across their security lifecycle, keeping the door open for the global security community to continue stress-testing the contracts in production.
For a contract that may custody billions in redeemable value, a single review was not enough. Flying Tulip used each layer for a different purpose: private audits for focused review, a contest for broader external pressure, and a bug bounty for ongoing coverage after deployment.
2,000+ Submissions. Zero Valid Mediums or Highs.
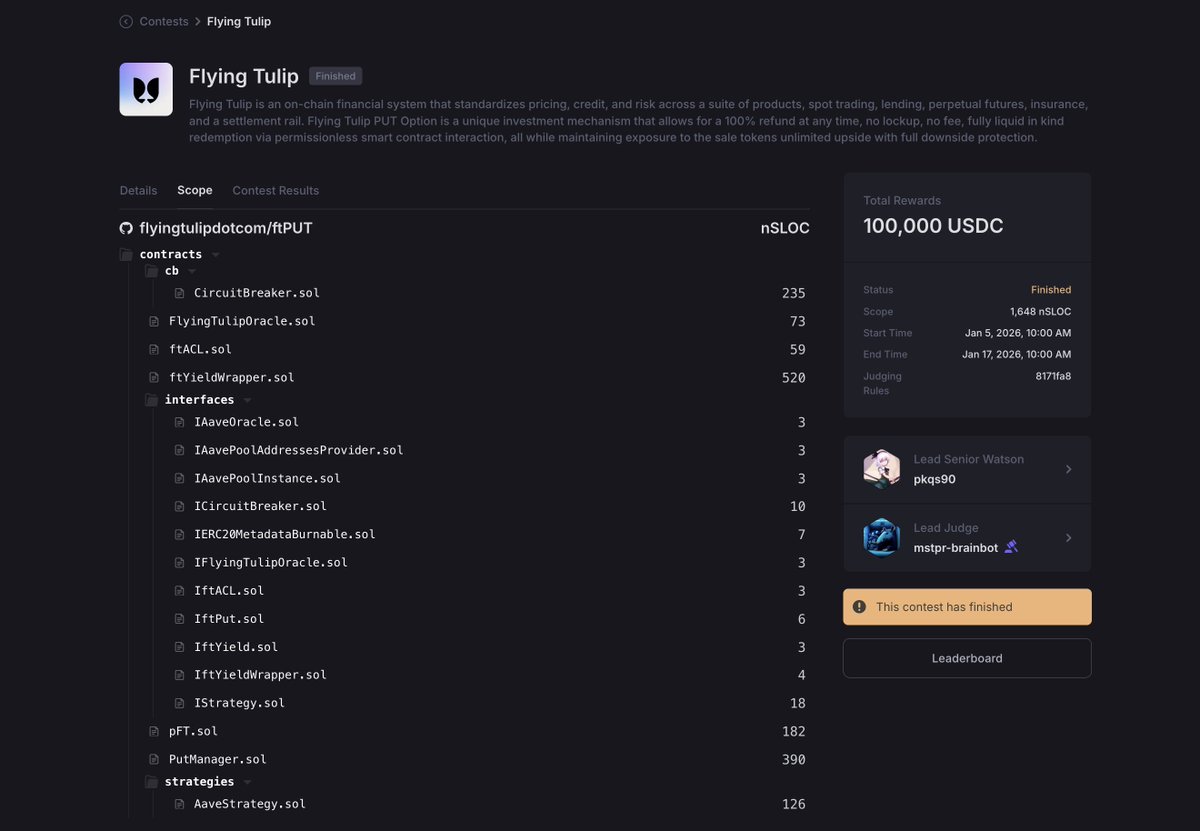
During the contest, hundreds of independent security researchers submitted more than 2,000 issues. From the outside, that number may have looked alarming.
High submission volume is normal in competitive review, especially on a high-profile target. Researchers test assumptions, edge cases, incentives, integrations, and implementation details from a myriad of different angles. Most submissions do not survive judging. That is part of the process.
After review and adjudication, the final count was clear: zero valid Medium or High severity findings.
The takeaway is not that risk disappears. It is that, under the contest scope and judging process, no submitted issue cleared the Medium or High severity bar.
What This Result Actually Proves
For Flying Tulip, the result supports the approach they took. They committed to a full security pipeline, ran every layer, and came out the other side with one of the cleanest contest outcomes we have seen on Sherlock.
For Sherlock, this is our audit contest model doing what it is designed to do: surface what researchers can find within a defined scope and judging process. Sometimes contests reveal severe vulnerabilities that save protocols from expensive incidents. Sometimes they show that prior review and internal hardening already removed the issues researchers were most likely to surface. Both outcomes are valuable.
The ftPUT codebase is live with a serious security foundation: multiple traditional audits, a Sherlock contest, and an ongoing bug bounty.
Every protocol going to mainnet with real value at stake should be asking whether their security process looks like this.
If it doesn’t, we should talk.

.png)
.png)